
Here’s some lock escalation behaviour that I found interesting and thought I’d share.
This is a link to all the T-SQL in this blog if you’d like to play along with me:-
Let’s start by creating a table with an identity column and some kind of data value that we’re interested in also stored as an INT.

By default, SQL Server creates a clustered index when a primary key is declared, but sometimes we might not want this. Here, ID is an artificial key whose value has no real world meaning. Queries are unlikely to reference it as a predicate, so instead we’ve declared the clustered index on another column which does contain real world values more likely to be used as query predicates. This is not an uncommon thing to do.
We’ll now insert some values into the table using a pre-created numbers table. If you don’t have one of these already then just refer to the attached script to create one.

So let’s recap – we have a 200 row table, which contains 200 rows – 100 rows for the year 1666 and 100 rows for the year 1812.
Let’s try to delete all the rows for one of those years (we’ll do this inside a transaction that we’ll keep open just so we can monitor the locking and then roll back the deletion).

Now let’s open up a second query session in Management Studio, and from this other query we’ll delete the rows corresponding to the other year value.

Both deletions are able to succeed, if we execute sp_lock we can see why.
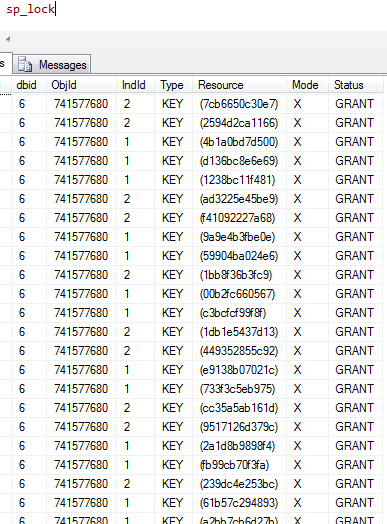
SQL Server has effectively taken out a lock on every individual row that we are asking it to delete.
Actually, there are 400 locks, because 100 rows are being deleted in each of the 2 sessions – but a lock is acquired on both cluster index and primary key for each (100 x 2 x 2).
So, all seems good so far. Our 2 separate sessions have happily deleted the rows that we have asked them to, and neither has trodden on the other’s toes.
Let’s roll back the deletions in both the first session…

…and second query session that we have open.

Now let’s see how things behave when we repeat the same test but with a larger quantity of data. First we’ll increase the number of occurrences of each of our 2 values up from 100 to 15000.

Now, exactly as before we’ll try to delete all the rows for one of those years…

…and in the second query session we’ll delete the rows corresponding to the other year value.

Things behave a little differently this time. The first deletion completes but the second sits there whirring away indefinitely – unable to complete. A call to our friend sp_lock tells us what has happened:-

We can see that this time, instead of a series of individual row locks, the first session has taken out a lock on the whole table. This is now blocking the second session since all the rows it needs to get at have already been locked.
The reason for this behaviour is well documented (and is not the puzzling behaviour to which I was referring). Each lock that SQL Server has to create takes resources and creating many locks therefore takes a lot of resources.
SQL Server defends itself against running out of resources by a process known as lock escalation. Books Online describes this fairly succinctly…
“Lock escalation is the process of converting many fine-grain locks into fewer coarse-grain locks, reducing system overhead while increasing the probability of concurrency contention”.
Indeed this is exactly what we are seeing here. SQL Server realises that creating a lock on so many rows is going to be a very resource intensive operation for it, so it has locked the whole table instead. Good news for resource management, bad news for concurrency (our second session trying to delete rows).
Let’s again roll back the transaction in the first session…

…and stop the deletion and roll back the transaction in the second query session .

So, we need a way to keep this resource preserving behaviour that we’re seeing, but at the same time without completely sacrificing concurrency. One solution to this is of course table partitioning.
With a partitioned table, we increase concurrency by allowing SQL Server an additional level of locking to employ – the partition level. This preserves resources (by allowing many row locks to escalate to a single partition lock) without locking the entire table – thus giving other sessions a chance to do some work at the same time.
Let’s see how this idea works out for us. We’ll create the partition function and scheme:-

We’ll change the lock escalation on the table to allow SQL Server the ability to lock at the partition level:-

We’ll then partition the table by recreating the clustered index on the partition scheme:-

Our table is now nicely partitioned, separating out the 2 values for year that we have in our table into 2 separate partitions. This should solve our previous concurrency problem.
Now, once again we’ll try to delete all the rows for one of those years…

…and in the second query session we’ll delete the rows corresponding to the other year value.

We can now see how well partitioning has fixed the concurrency problem.
It hasn’t.
The second session is still unable to complete and a quick look at sp_lock will once again show that the first session has acquired a table lock – even though SQL Server should surely be taking out a much more environmentally friendly partition lock:-

This behaviour had me scratching my head.
After all, we’ve partitioned the table on the Puzzle_Year column, and our delete commands are predicated on Puzzle_Year. Surely SQL Server should be using partition-level locking here?
The dynamic management view sys.partitions gives us a clue:-

Index 1 (the clustered index) is clearly partitioned into 3.
Index 2 (the primary key) clearly isn’t.
So SQL Server can’t escalate from key lock to partition lock for this primary key (since it isn’t partitioned) – and is therefore escalating straight to table lock.
Once again let’s roll back the transaction in the first session…

…and stop the deletion and roll back the transaction in the second query session .

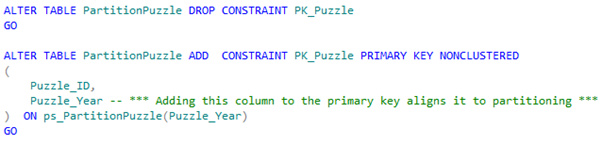
Now let’s align the Primary key to the partitioning scheme. We can do this by adding the partition key to the primary key:-
Let’s repeat our test one more time…

…and in the second query session…

Finally, we have the behaviour that we hoped for:-

You can see that the first session has a single partition lock on the primary key and clustered index, whilst the second session has locked another single partition on the primary key and clustered index.
(The table locks indicated are not eXclusive).
Finally we have achieved our economy and concurrency.
Just worth mentioning though that in the process of solving this puzzling behaviour we’ve also created what database theorists would call a “super key”.
Despite its name, a super key isn’t good. It means that we’ve taken a unique key (the ID column) and then added something else to it (the Puzzle_Month column) which it didn’t need since it was already unique in the first place.
However in this scenario it seems to be the only way to achieve the outcome that we wanted.
Thanks to my friend Ceri for helping me with this puzzling behaviour.
