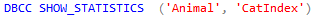It takes a lot of time to create SSRS e-mail subscription recipient lists when there are a large number of recipients, and all you have are the recipients’ human names.
I wrote a PowerShell function to take a list of names and generate all the recipients’ e-mail addresses from AD in an SSRS friendly format.
I hope this will save you some time when you are creating SSRS subscriptions like this too.
Here’s the scenario; you’re asked to create one or more new SSRS e-mail subscriptions, and you’re provided with the desired recipients’ human names in a long list, perhaps via an e-mail from someone, like this:-
Robert Smith
Alan Jones
William White
Victor Stephenson
Maria Brown
Helen Wood
etc.
Assuming that the organisation you’re working in doesn’t create an AD distribution group per subscription (and I’ve never seen that done), you will need to work through the list of recipients, and for each one look up their individual e-mail addresses manually, and then add them piecemeal to the subscription.
To save the time and hassle doing this, I wrote a PowerShell function to query Active Directory for the e-mail addresses of the accounts matching the names from the list, and then generate a long string of these e-mail addresses with semi-colon separators.
So given the above list, we will end up with something like this:-
robert.smith2@ricketyrocket.com; alan.jones1@ricketyrocket.com; will.white@ricketyrocket.com; victor.stephenson@ricketyrocket.com; m.brown@ricketyrocket.com; helen-jane.wood@ricketyrocket.com; mick.smith@ricketyrocket.com; julie.stirrup@ricketyrocket.com; d.delante@ricketyrocket.com; chris.woode@ricketyrocket.com; christian.browne@ricketyrocket.com; brenda.chapel@ricketyrocket.com; maurice.laurence@ricketyrocket.com; Dan.Delaney@ricketyrocket.com; cynthia.knott@ricketyrocket.com; linda.bell@ricketyrocket.com
The function then automatically copies the string to the clipboard so that it can then be pasted straight into the SSRS report subscription recipient box – saving time and avoiding the risk of a typo.
The function de-duplicates the source list of names, in case the same name has been inadvertently added to the list more than once (thus avoiding the same e-mail address being added to the output string more than once).
If multiple e-mail addresses exist for any name in the list, this most likely means that multiple AD accounts must have the same name property e.g. you have two people in your organisation named John Smith. In this situation the function adds all e-mail addresses matching the name in question to the output string. However a warning is issued, advising that any undesired e-mail addresses should be removed from the list manually.
WARNING! – Multiple AD accounts exist with the name Will White (will.white@ricketyrocket.com will.white2@ricketyrocket.com)
Please review the final e-mail address string and remove any that are not required.
Naturally the human names specified in the list need to be the same as they are defined within Active Directory. So for example if the name is “Bob Smith” in the list, but “Robert Smith” in AD then there won’t be a match. Additionally people obviously need to have an e-mail account defined within Active Directory.
In the event of either of these two failings, an alert is displayed like this:-
Mark Madeup not found in Active Directory, or doesn’t have an e-mail address.
Please check the name e.g. Robert instead of Bob etc.
Also check that this person has an e-mail address defined.
To use the function, simply:-
(i) Create the function by running the PowerShell script below.
(ii) Copy the list of desired recipient names from the source (e.g. e-mail) into a text file.
(iii) Call the function with a single parameter, giving the path to the text file like this:-
Get-AddressList -File C:\temp\Folks.txt
(iv) Paste the contents of the clipboard into the recipient box for the subscription:-

Here’s the script to create the function, I hope that you will find it useful:-
Function Get-AddressList
{
<#
.SYNOPSIS
Given a list of human names, generates a string of their associated e-mail addresses.
.DESCRIPTION
Reads a text file containing a list of human names, and returns e-mail addresses
for those names by querying Active Directory.
E-mail addresses are returned in a string separated by a semi-colon and space,
which is automatically copied to the clipboard ready to be pasted into an SSRS subscription.
A problem is indicated for any names that cannot be resolved to an e-mail address.
A warning is indicated for names that resolve to more than one e-mail address
(e.g. multiple AD accounts with the same name).
It is left to the operator to review the final address string and remove the e-mail
adresses that are surplus to requirements.
.NOTES
Version: 1.0
Author: Andy Hogg
.PARAMETER FileName
Specifies the text file name containing the list of human names.
.INPUTS
None. You cannot pipe objects to Get-AddressList.
.OUTPUTS
System.String. Get-AddressList returns a string of e-mail addresses and copies this to the clipboard.
.EXAMPLE
Get-AddressList -File “c:\temp\folks.txt”
.LINK
https://andyhogg.wordpress.com/2016/03/05/generate-ssrs-subscription-e-mail-addresses-from-ad-4
.LINK
http://msdn.microsoft.com/en-us/library/ms156307.aspx#bkmk_create_email_subscription
#>
[cmdletbinding()]
PARAM
(
[parameter(Mandatory=$true)]
[string] $File
)
#Read the list of names from the file
[Array]$Users=get-content $File
#Remove any empty lines from the end of the file
$Users = $Users | where {$_ -ne “”}
#Deduplicate names
$Users = $Users | Sort-Object | Get-Unique
[String] $Recipients = ” #The final list of e-mail addresses
[String] $Multiples = ” #Names and addresses matching more than one AD account
[Array] $Addresses = ” #The e-mail address(es) associated with the current name
#Iterate over each name from the list
foreach ($User in $Users)
{
Try
{
#Query AD for e-mail address for the current name
$Addresses = Get-ADUser -Filter ‘Name -like $User’ -Properties mail |
select -ExpandProperty mail
#If more than one AD account matches the name, then note the details
if ($Addresses.Count -gt 1)
{
$Multiples = $Multiples + $User + ” “ + “($Addresses) “
}
#If there’s no e-mail address then throw an error
if (!$Addresses) {throw}
#If there is an e-mail address or addresses then add them to the list of recipients
for ($i=0; $i -lt $Addresses.count; $i++)
{
$Recipients = $Recipients + $Addresses[$i] + ‘; ‘
}
}
#Catch block for names not found in AD or names without an e-mail address
Catch
{
cls
Write-Host `n
Write-Host “PROBLEM! – $User not found in Active Directory” -ForegroundColor Red
Write-Host “Or doesn’t have an e-mail address.” -ForegroundColor Red
Write-Host “Please check the name e.g. Robert instead of Bob etc.” -ForegroundColor red
Write-Host “Also does this person have an e-mail address defined?” -ForegroundColor red
Write-Host `n
Return
}
}
#Remove the trailing space and semi-colon from the final list of recipients
$Recipients = $Recipients.Substring(0,$Recipients.Length–2)
cls
Write-Host `n
#If multiple AD accounts exist for the same name, alert to this fact
if ($Multiples.length -gt 0)
{
write-host “WARNING! – Multiple AD accounts exist with the name $Multiples“ -ForegroundColor Red
write-host “Review the final e-mail address string and remove those addresses not required.” -ForegroundColor Red
}
#Write the full list of e-mail addresses
Write-Host `n
Write-Host “The full list of recipient e-mail addresses is:-“
Write-Host $Recipients -ForegroundColor Cyan
#Copy them to the clipboard
$Recipients | clip
Write-Host `n
Write-Host “This string of addresses has already been copied to the clipboard”
Write-Host “and is ready to be pasted intothe recipients box of an SSRS e-mail subscription.”
Write-Host `n
} #Close function block

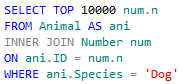
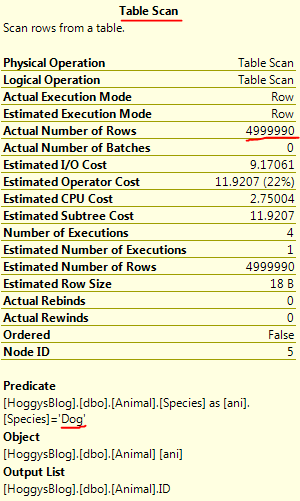
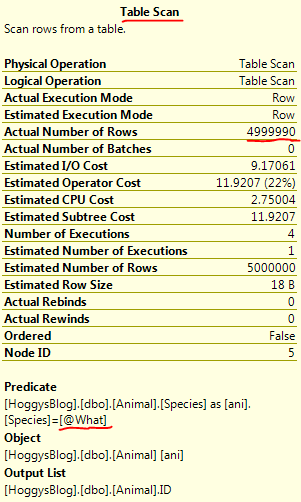
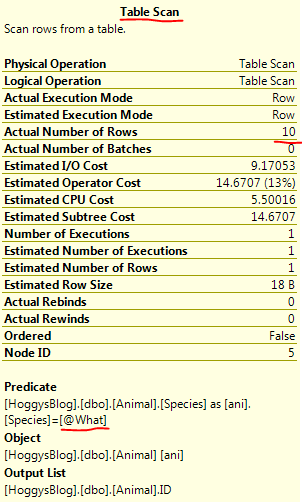
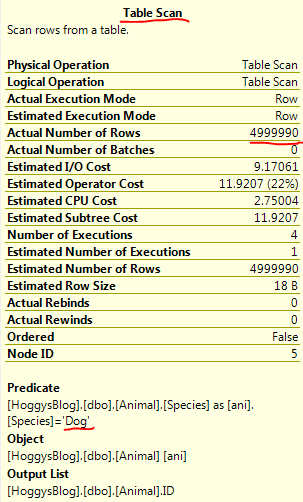
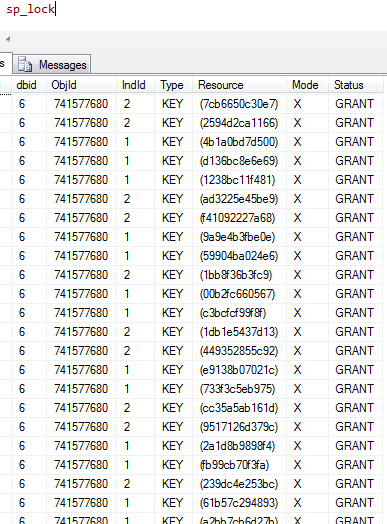
 Just a couple of quick notes from playing around with the T-SQL
Just a couple of quick notes from playing around with the T-SQL
![image_thumb10[1]](https://andyhogg.files.wordpress.com/2019/01/image_thumb101.png "image_thumb10[1]")